

It's been a while since we've published news about Dataflow Kit services. We are so excited to present a new, completely re-implemented Dataflow Kit! 🥳
We improved our legacy web scraper engine and Visual Point-and-Click tool. Also, let us introduce our new, more focused, and more understandable web services.
Find below brief information about the new exciting features/ services we provide.
New services:
- Download web page content with Headless Chrome in the cloud.
- Web Scraper with worldwide proxy network support.
- SERP data collector.
- URL to PDF Converter.
- Capture Screenshots from web pages.
 Download web pages.
Download web pages.
Fetching content from server-side rendered (SSR) web pages is not a complicated task. It may be performed with a simple cURL command in general. We help to automate the download of SSR (static) web pages with "Base Fetcher" by querying Dataflow Kit API.
Heavy JavaScript Frameworks are used in most modern web sites. So it may be challenging to fetch dynamic content from such web pages. In this case, it is not enough to download a web page as is. We render dynamic content in our cloud with Headless Chrome ("Chrome fetcher") and return static HTML.
Certain websites may block repetitious requests coming in from the same IP address. We offer an option to use a global proxy network to resolve target websites' restriction issues.
Sometimes users demand to execute some simple actions upon visiting a web page. Actions simulate real-world human interaction with a page. Find more information about action types in the corresponded section below.
That's why the DFK Web page download service exists.
 Build Custom Web scraper.
Build Custom Web scraper.
Of course, we don't intend only to download web pages but to perform data extraction from them.
Users more often need to crawl several pages from a web site and extract structured data afterward.
The visual point-and-click toolkit helps to specify parts of data to extract.
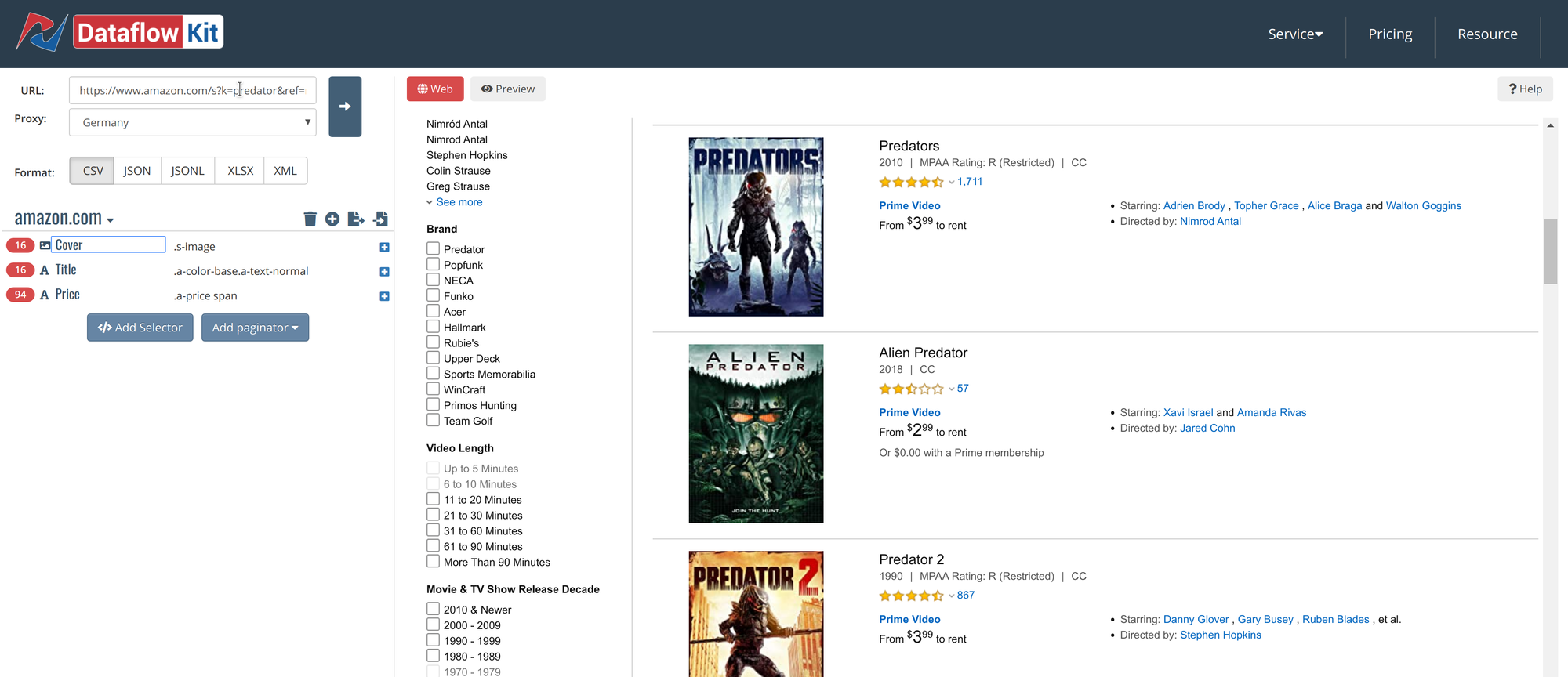
You can use web scraper for building web crawling and data extraction workflows.
 Scrape search engines.
Scrape search engines.
Search engines have always been one of the most valuable sources of data to scrape.
They crawl the web themselves to provide everyone with fresh content.
Using Dataflow Kit SERP extractor, you can collect data from the major Search engines, such as
- Google,
- Bing,
- DuckDuckGo,
- Baidu
- Yandex.
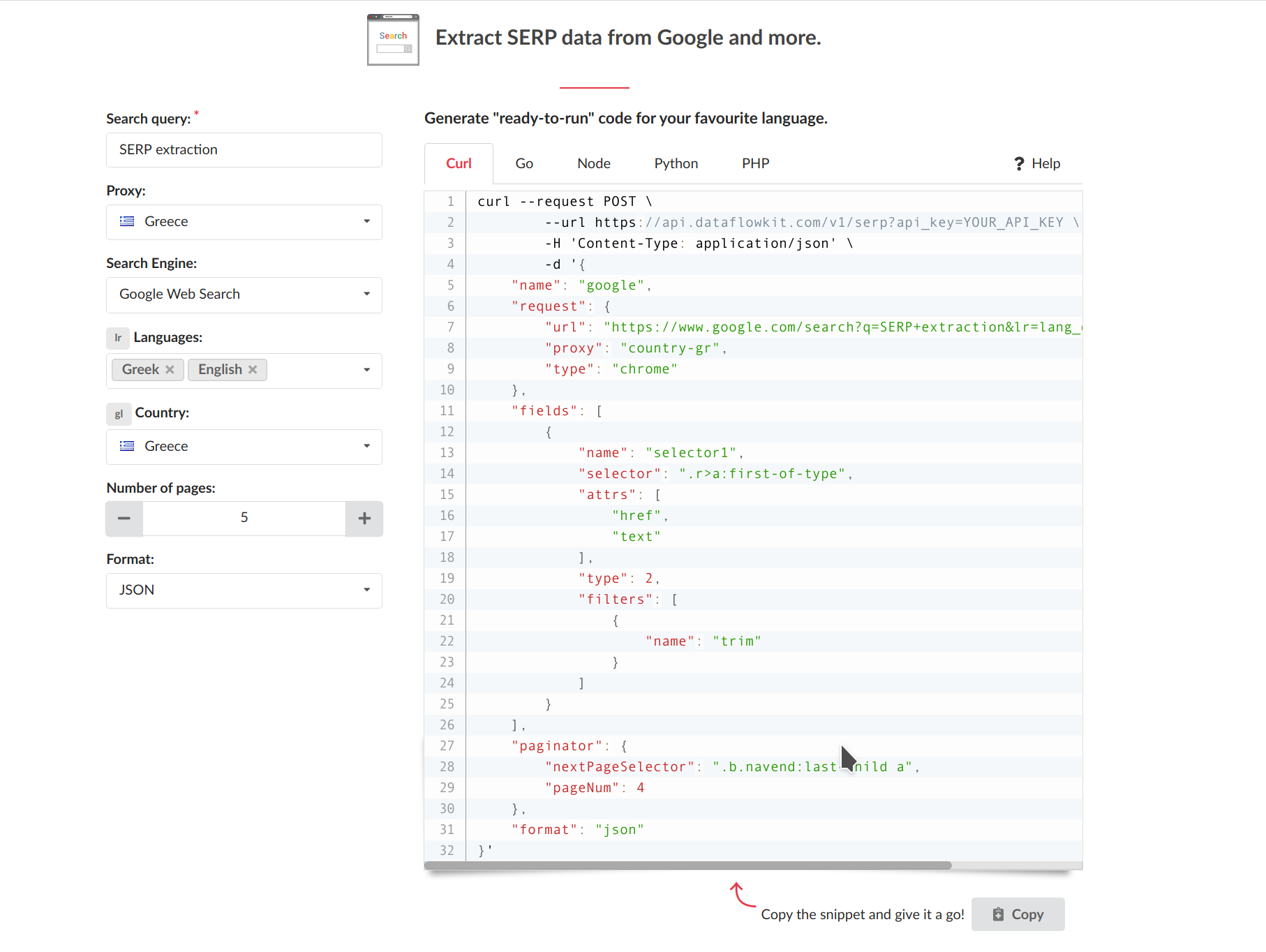
Tune Language and country settings to narrow your search. Only documents written in particular languages originated from specified countries are returned.
 Convert web pages to PDF.
Convert web pages to PDF.
There are many reasons to save a web page as PDF.
- You can view universal PDF format on any device, even offline.
- Archiving of websites preserves the content and layout of a document converted to PDF.
- It is not easy to interact with online documents in some cases. But if a web page in stored in a PDF format, you can highlight and markup your documents as you would any printed article or research paper..
The easiest way to convert a web page to PDF is to use any desktop browser.
So why use Dataflow Kit Web to PDF Converter? What makes it unique?
- Automate URL to PDF conversion right in your application. Send a request to DFK API specifying URL with Parameters to render a PDF file.
- Get resulted PDF even from websites blocked in your area for some reason utilizing our worldwide pool of proxies.
- Simulate real-world human interaction with the page. For example, before saving a web page to PDF, you may need to scroll it.
Check out URL to PDF Converter and try it yourself.
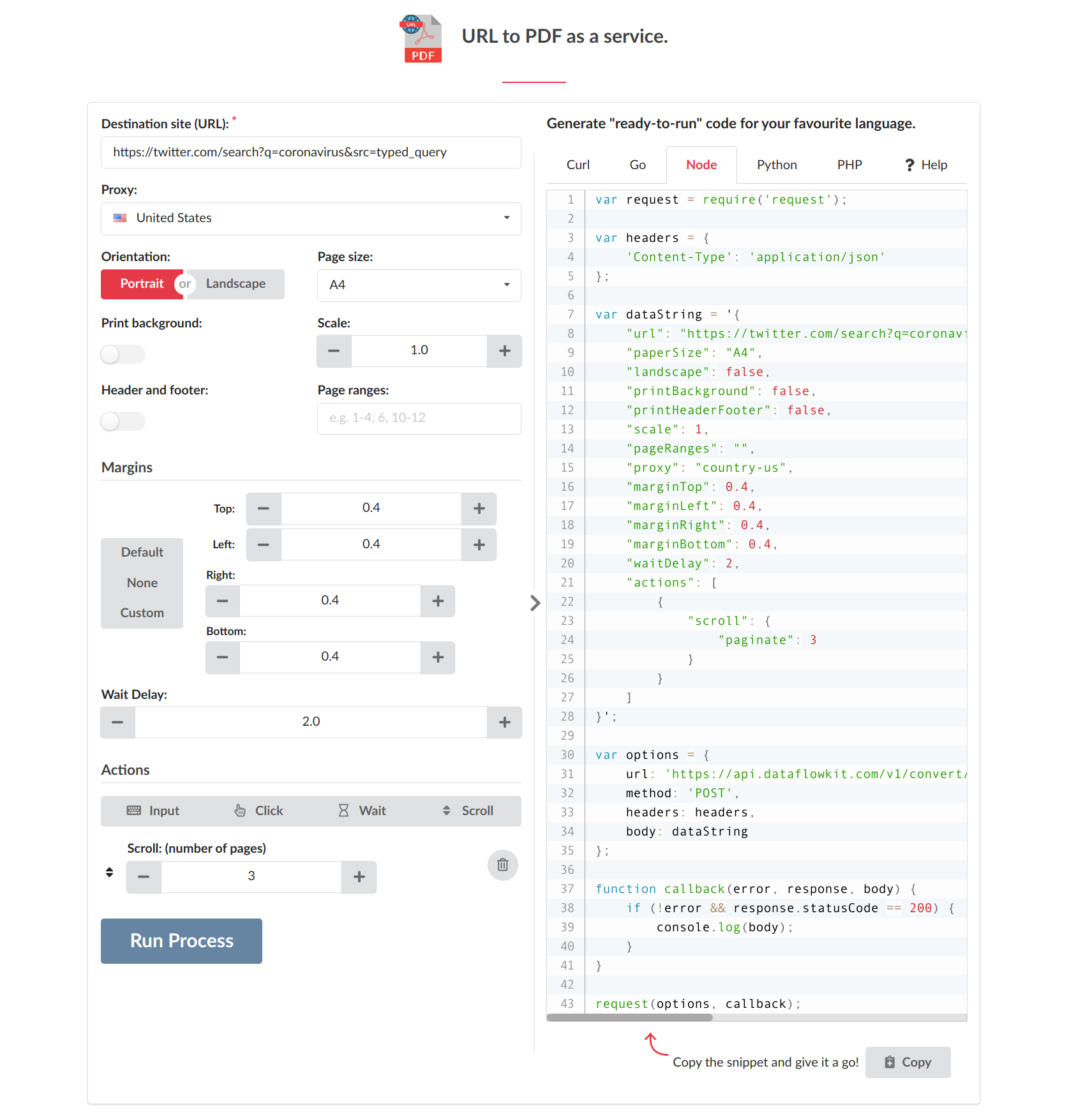
The same unique features listed above are available for the next service - Screenshot maker.
 Capture web page Screenshots.
Capture web page Screenshots.
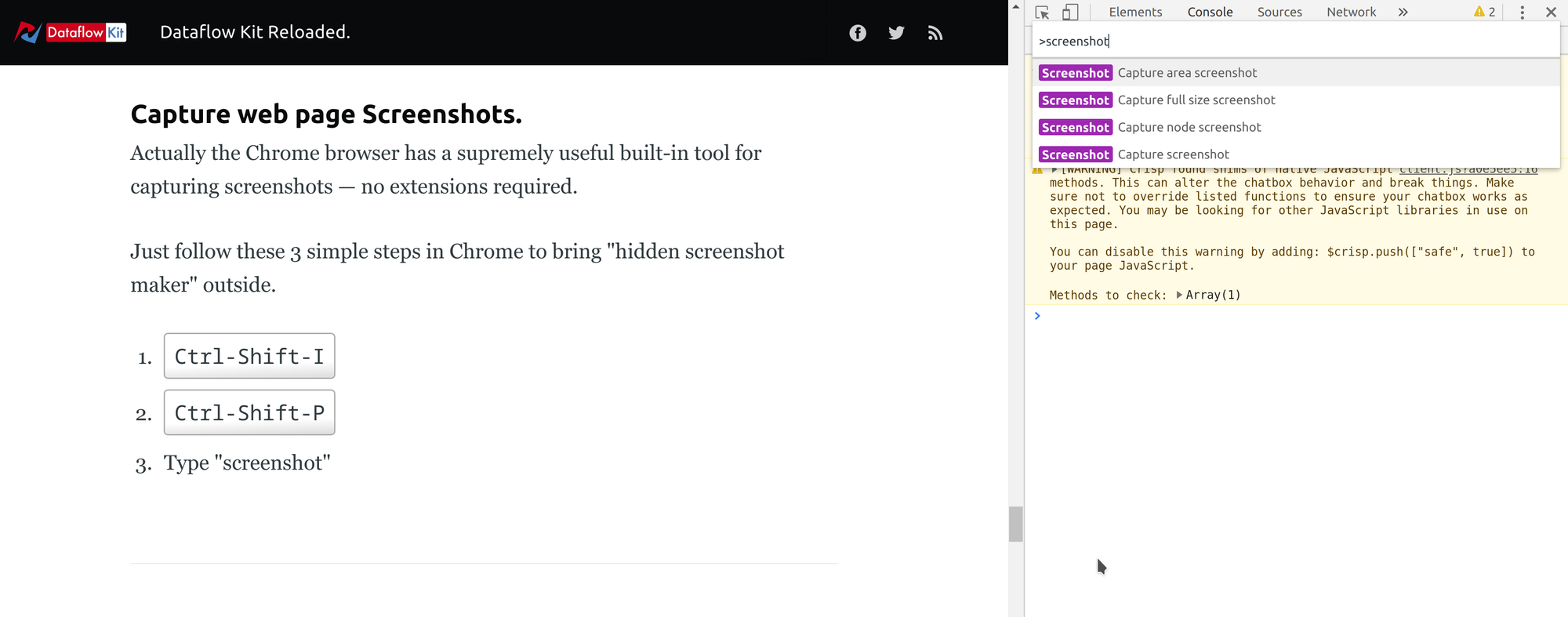
The Chrome browser has a useful built-in tool for capturing screenshots.
Follow these 3 simple steps in Chrome to bring "hidden screenshot maker" outside.
- Ctrl-Shift-I
- Ctrl-Shift-P
- Type "screenshot"
Allow me to outline some of the highlights of the screenshot capture service in our cloud.
- Capture web site screenshots right from your application written in Go, Node, Python, and more.
- Worldwide Proxies support.
- Actions emulate human interaction with web pages.

Generate "ready-to-run" code at URL to Screenshot service.
New features:
- Headless Chrome Browser in the cloud.
- Automation of manual workflows. Actions.
- World wide proxy Network
- Dataflow Kit API.
- Upload Scraped data to the most popular Cloud Services.
- User dashboard.
Headless Chrome as a service.
We run several Headless Chrome browser instances in our cloud. They used for rendering JavaScript-driven dynamic web pages to Static HTML and automating different actions with web page i.e.
- scrape specific elements;
- take screenshots;
- create PDFs and more.
Automation of manual workflows. Actions.
Actions help to interact with web pages.
Here is the list of available actions:
- 'Input action' - Specify Input Parameters to perform search queries, or fill forms.
- 'Click action' - Click on an element on a web page.
- 'Wait action' - Wait for the specific DOM elements with which you want to manipulate.
- 'Scroll action' - Scrolls a page down to load more content.
Actions are performed by scraper upon visiting a Web page helping you to be closer to desired data.
Worldwide proxy Network
Many popular websites provide different, personalized content depending on user location. Sometimes websites restrict access to users from other countries.
We offer "Dataflow kit Proxies service" to get around content download restrictions from specific websites. Another use case of Proxy Network is to obtain country-specific versions of target websites.
Send your Web/ SERPs scraping API requests through the one of specified from about 100+ supported global locations.
Dataflow Kit API.
Use our REST API to fetch web page content, request SERP data, capture Screenshots of websites, or generate PDFs right from your application. Specify parameters for built-in code generators on services' pages to generate "ready-to-run" code for your favorite Language including:
- cURL,
- Go,
- Node,
- Python
- PHP.
For a more comprehensive overview, check out DFK API Documentation.
Output data formats. Upload results to Clouds.
You can choose the desired output format from the list below to save scraped data.
- CSV,
- JSON (Lines),
- Excel or
- XML
To provide you with high availability and scalability when saving results, we use AWS S3 compatible storage. Besides, you can upload Search results data to the most popular cloud providers, including:
- Google Drive;
- DropBox;
- Microsoft Onedrive.
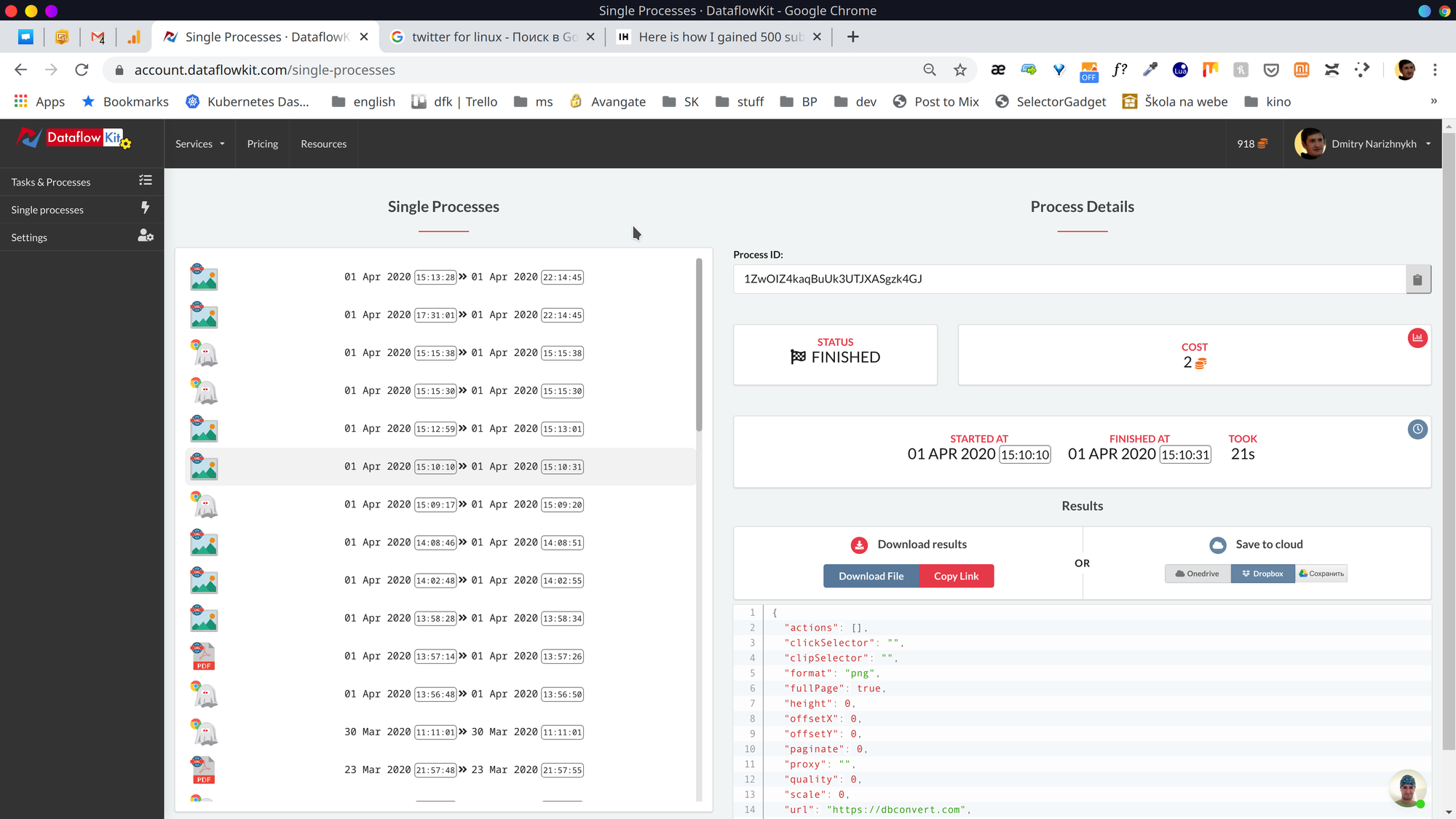
User dashboard.
You can access your account details and manage your API, Tasks, and Processes after login to your dashboard.
Conclusion
Hopefully, these more targeted services, coupled with new features, help you to automate web scraping and data conversion tasks more efficiently.
If anything was unclear, feel free to send us a message - We'd love to help!
Tweet